Setup local LLMs & Embedding models¶
Prepare local models¶
NOTE¶
In the case of using Docker image, please replace http://localhost with http://host.docker.internal to correctly communicate with service on the host machine. See more detail.
Ollama OpenAI compatible server (recommended)¶
Install ollama and start the application.
Pull your model (e.g):
Setup LLM and Embedding model on Resources tab with type OpenAI. Set these model parameters to connect to Ollama:

oobabooga/text-generation-webui OpenAI compatible server¶
Install oobabooga/text-generation-webui.
Follow the setup guide to download your models (GGUF, HF). Also take a look at OpenAI compatible server for detail instructions.
Here is a short version
Use the Models tab to download new model and press Load.
Setup LLM and Embedding model on Resources tab with type OpenAI. Set these model parameters to connect to text-generation-webui:
llama-cpp-python server (LLM only)¶
See llama-cpp-python OpenAI server.
Download any GGUF model weight on HuggingFace or other source. Place it somewhere on your local machine.
Run
Setup LLM model on Resources tab with type OpenAI. Set these model parameters to connect to llama-cpp-python:
Use local models for RAG¶
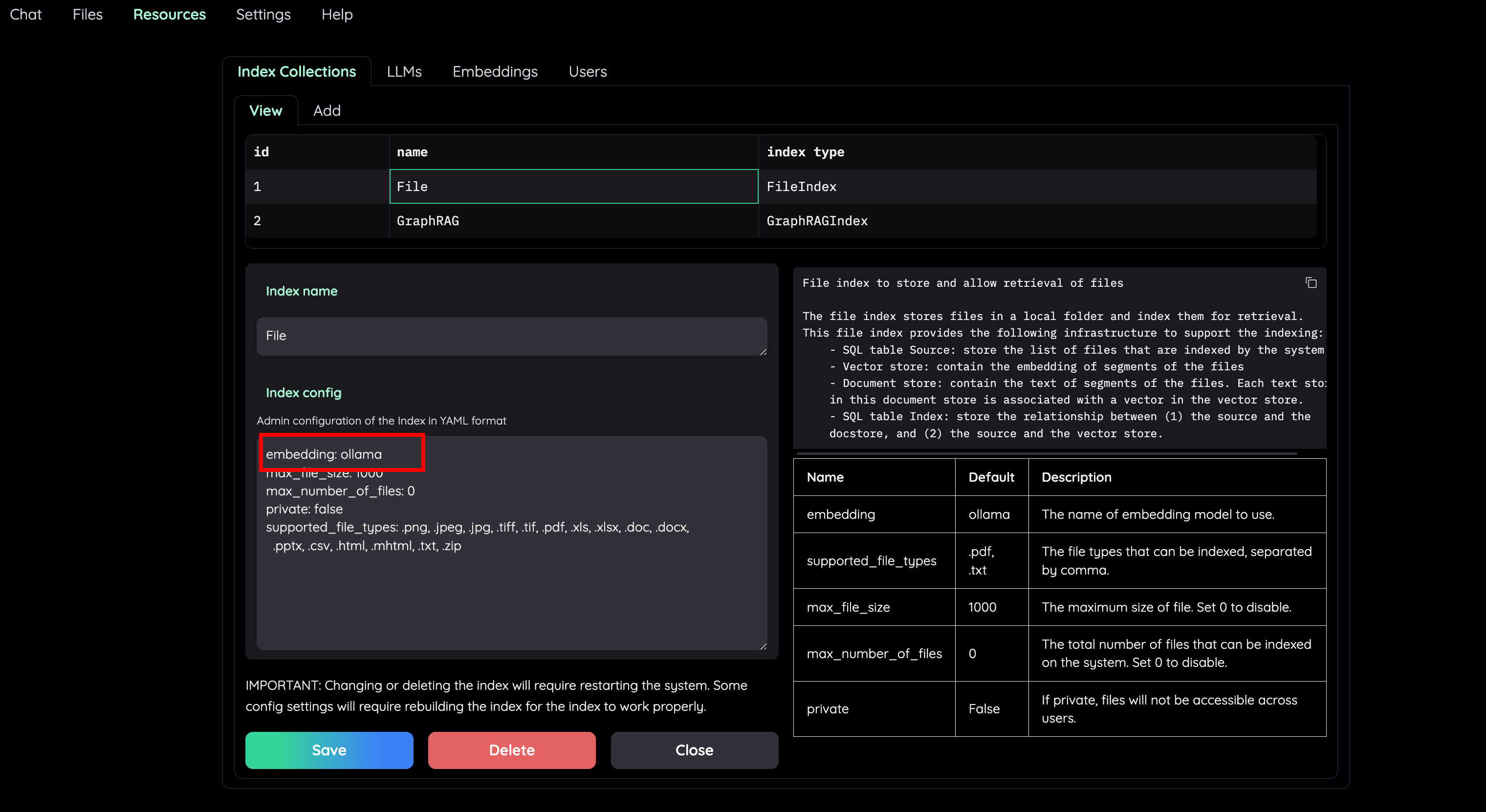
- Set default LLM and Embedding model to a local variant.
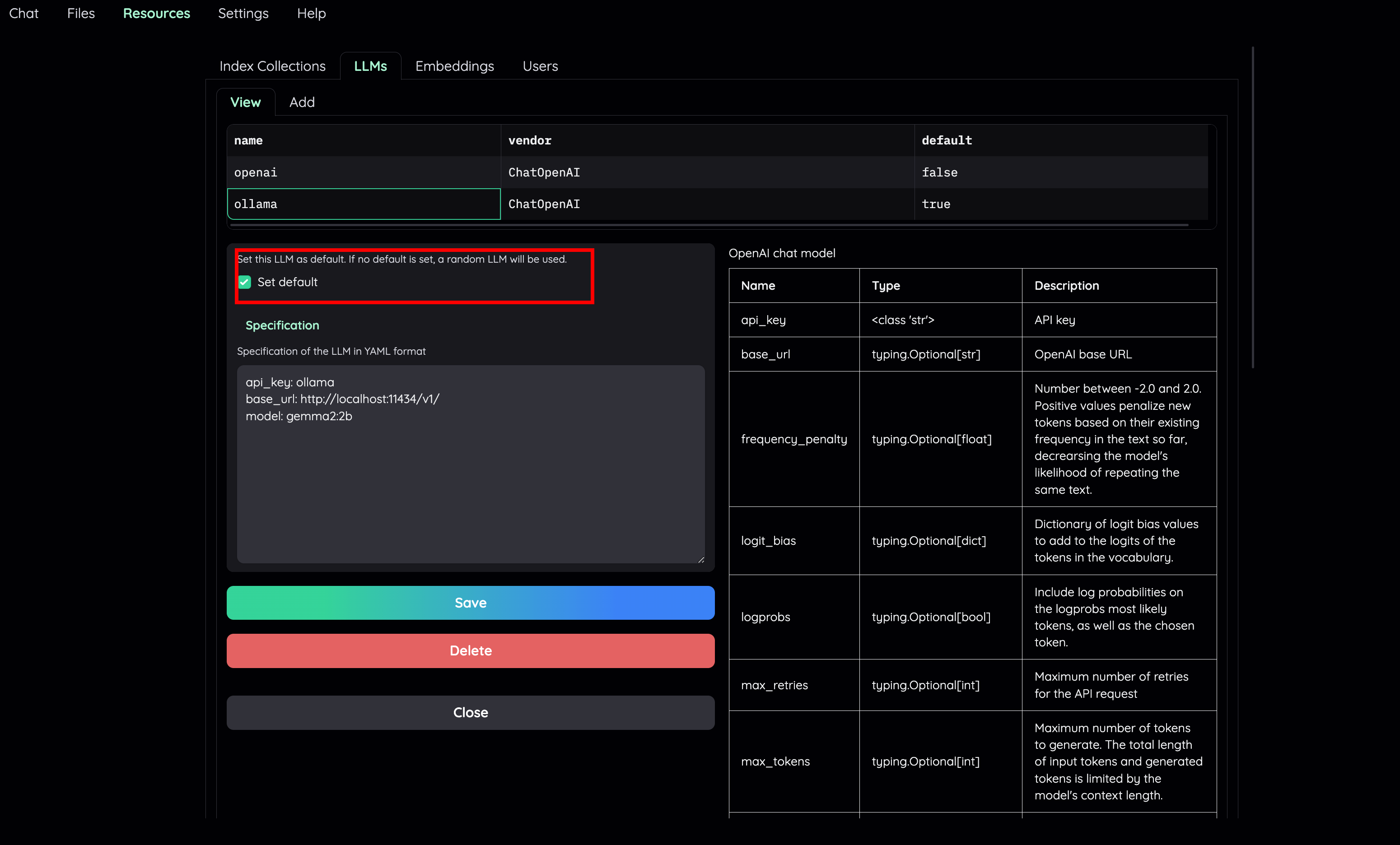
- Set embedding model for the File Collection to a local model (e.g:
ollama)
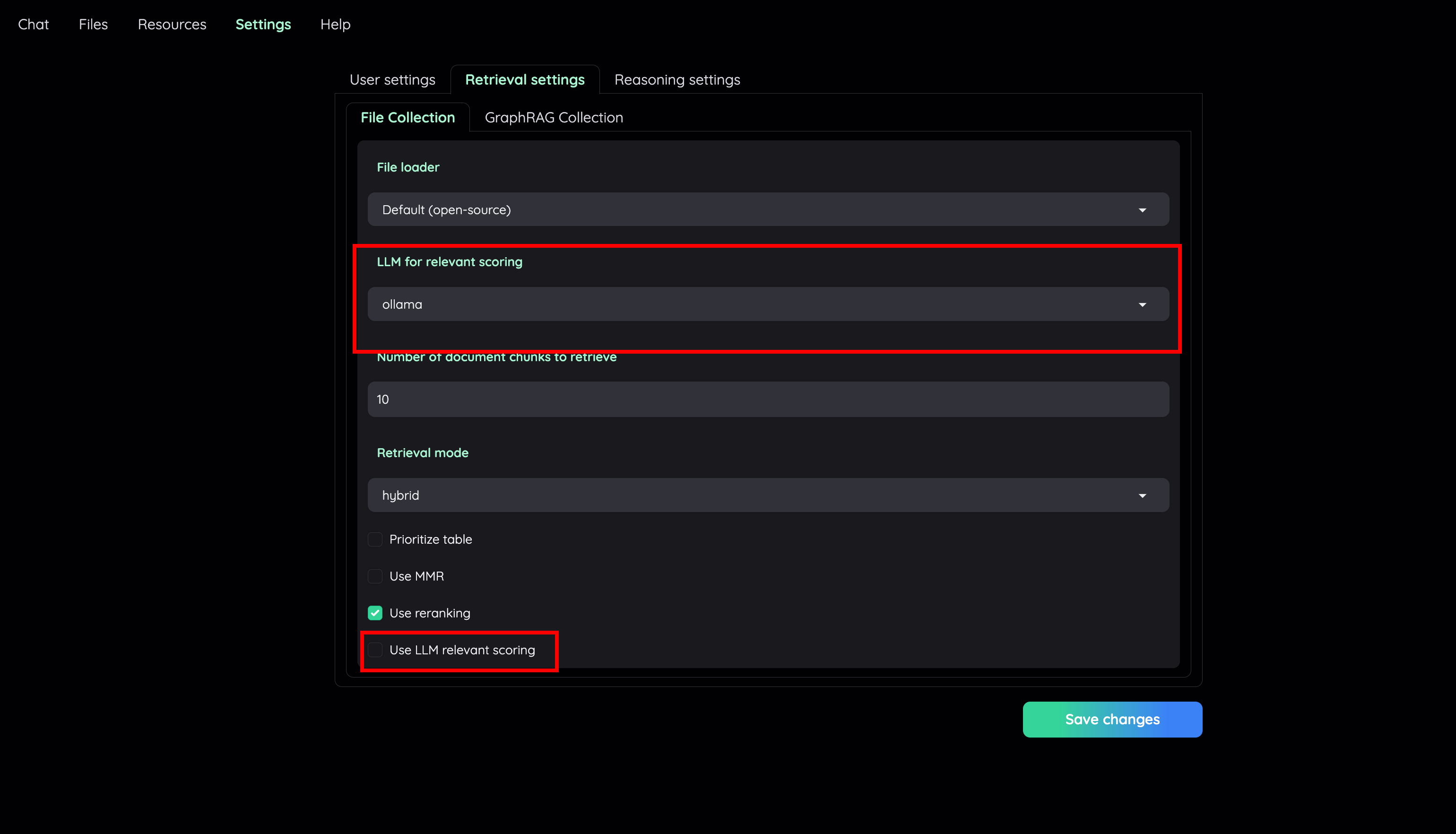
- Go to Retrieval settings and choose LLM relevant scoring model as a local model (e.g:
ollama). Or, you can choose to disable this feature if your machine cannot handle a lot of parallel LLM requests at the same time.
You are set! Start a new conversation to test your local RAG pipeline.